誤解されています
Ahlqvist博士が,『2型糖尿病という病気は存在せず,全く異なる複数の病気に分類すべきだ』としたこの論文については,最近ちらほらと引用されるようになりました.

しかし,この分類を行った方法について 誤解している人もいるようです.
Ahlqvist博士は,たしかに糖尿病に関連する6つの指標(下記)をてがかりにして,従来の糖尿病を分類し直したのですが;
- GAD抗体の有無
- 発症年齢
- HbA1c
- BMI
- HOMA2-β
- HOMA2-IR
しかし,これらの指標を使って従来の2型糖尿病患者のデータを分類するにあたり,例えば
- HOMA2-β がいくつ以下とCutOff値を決め,かつBMIが 20未満の人..の人は『インスリン分泌不全型』としよう
- HOMA2-R がいくつ以上あって,BMIが30以上の人は『インスリン抵抗型型』に分類しよう
- ...
【などというようなやり方で分類したのではないのです】
つまり,あらかじめ分類基準を決めておいてから 糖尿病患者のデータを仕分けしていったのではないのです.
そんな方法であれば,患者データが1万人だろうと10万人だろうと,Excelに式を放り込んで ものの20分もあれば『分類』は完了します.
そうではなくてData-driven Cluster Analysisという方法を用いたのです.
Data-driven Cluster Analysisとは
以前の記事にも書きましたように,Ahlqvist博士はスウエーデンで新規に糖尿病と診断された患者の一人一人のデータを,ちょうど子供が『オハジキ遊び』をするように,6つの指標データが近いもの同士をグループにまとめていったのです.
しかし その操作は,人間が行ったのではなくて コンピュータが行いました. というより,コンピュータでなければ到底不可能なやり方でした.
話を分かりやすくするために,データの指標を6つではなくて,2つ(たとえば HbA1cと BMI)を用いたとします.
【手順 1】
BMIを横軸に,HbA1cを縦軸にとり,すべての患者のデータをプロットします.
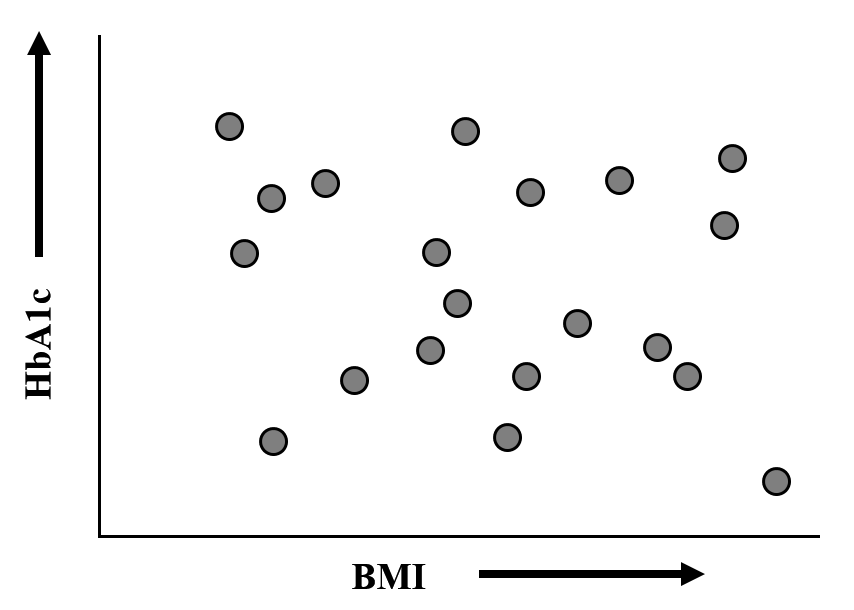
【手順 2】
一見バラバラのようでもあり,なんとなく過密なところ/過疎なところがあるようにもみえます.しかし,ここでは何も判断せずに,まず,グラフ上でデータが塊になっているところに適当に[重心:▲]を置きます.
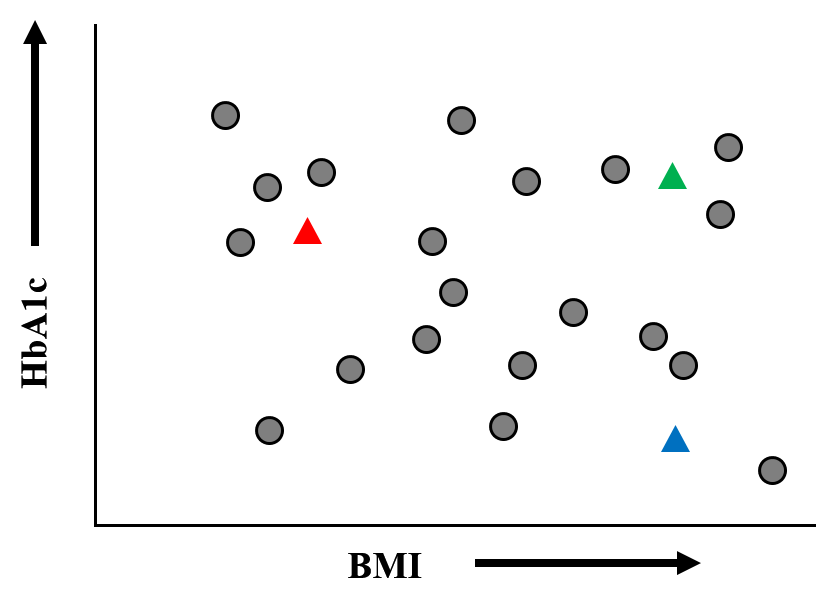
【手順 3】
そしてすべてのデータ(点)をランダムに 必ずどれかの重心に属するものとして割り当てます.ここまではまったく偶然に設定した重心に,これまた偶然に点を割り当ててグループ(クラスター)を作っただけです.
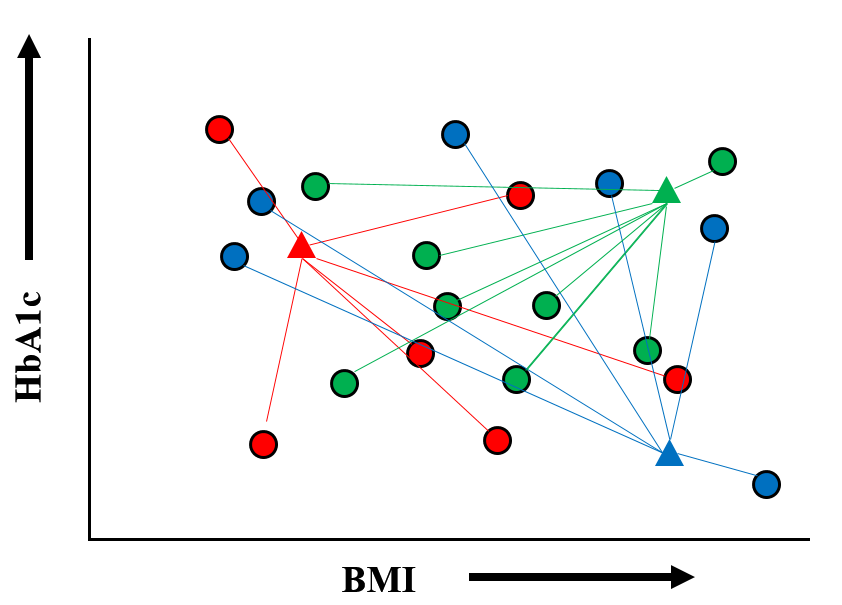
【手順 4】
次に 各グループごとに,そこに属するすべての点から 重心までの距離を計算し,それぞれのグループの新しい[重心]を定めます.この結果,最初に適当に設定した[重心]はなくなり,位置が変わりました.

【手順 5】
あらためてすべての点について,自分にもっとも近い[重心]を探し,『組替え』を行います.
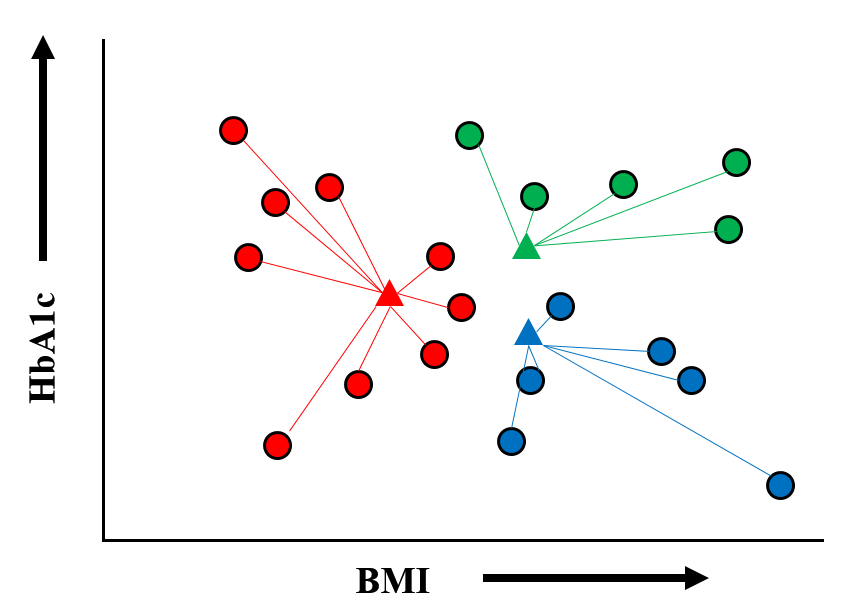
【手順 6】
新しいグループ分けに基づいて,各グループ内での重心位置計算をやり直します. これにより 重心の位置はまた少し動きました.
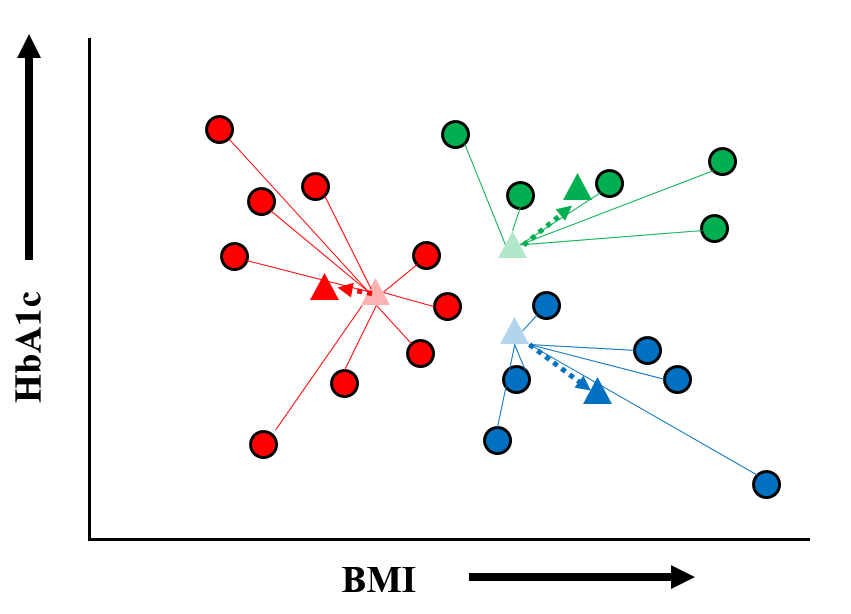
ここで,また【手順 5】の『組替え』に戻り,【手順 6】→ 【手順 5】→ 【手順 6】...を,もはやすべての重心の位置が変わらなくなるまで繰り返します.次第に重心の動きは小さくなり,最後には すべての点が 最適な[重心]に属するようになります.すなわちグループ分け(=クラスター分析)の完了です.
以上の例では,2個の指標を使ったので,すべての点は[x,y]の2次元平面にあるものとして計算しました.しかし,もしも使う指標が3個だったら,データは三次元空間の座標[x, y, z]を持ちます.Ahlqvist博士は6個の指標を使ったので,すべての点(9,000個の点ですよ!)を6次元空間に配置して,それらすべての点間の距離を求め,重心を求め…とやったわけです.気の遠くなるような計算量がおわかりいただけるでしょうか.もはや手計算はおろかExcelでもどうにもなりません.プログラムを組んでスーパーコンピュータが必要なのです.
このようにして求まったグループ分け,それが Data-Driven Cluster(データによって定まった塊)です.この操作は,ただ『似た者同士』を寄せ集めていっただけであり,データ個々の値については考慮していません. あくまでも『似ているかどうか』だけを判定していったのですから.
ところが,それにもかかわらず,従来『2型糖尿病』とひとくくりにされていたものが,それぞれ特徴を持つ明瞭なクラスターに分かれることが判明したのです. しかもそのクラスターに属する患者の合併症の推移を追跡してみると,異なるクラスターでは,合併症の傾向や進行速度に大きな差があったのです.特に SIDD(=重度インスリン分泌不全糖尿病)の網膜症リスク,SIRD(=重度インスリン抵抗性糖尿病)の腎症リスクは,他のクラスターとはまるで違っていました.つまり 2型糖尿病でも,腎症になりやすいクラスターと,あまり発症しないクラスターとがあると判明したのです.
[5]に続く


コメント