多くの方のご協力のおかげで,「自分の糖負荷試験の結果はこうだった」という生データが集まっています.
途中経過のご報告です
まだデータの解析にまでは至っていませんが,手元に集まったデータを眺めた段階だけでも驚きました.データのご提供はまだ続いていますが,とりあえず現時点までのデータ一覧をまずご覧ください.
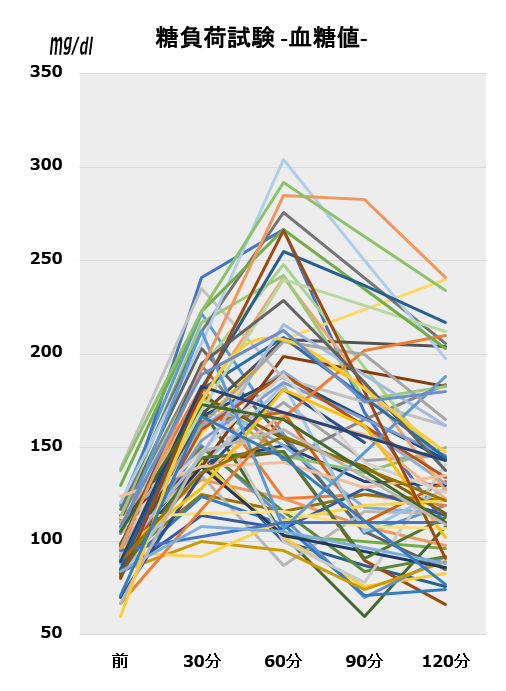
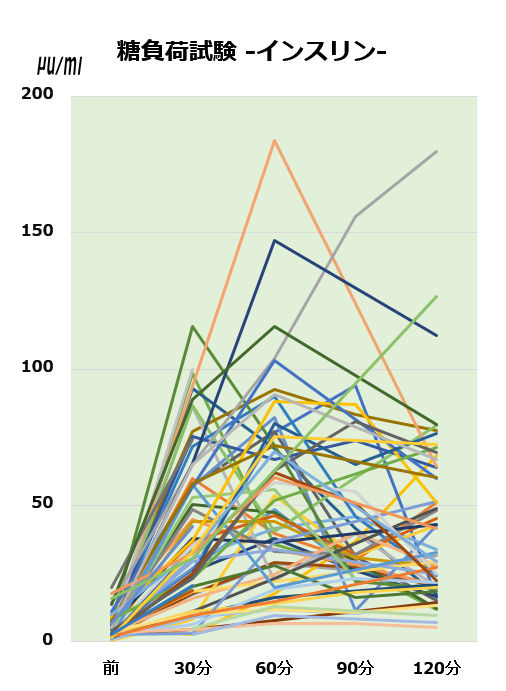
何という多様性
上のグラフには 納先生のHP に掲載されていた26人の方のデータも含まれています[*]が,それにしても完全にバラバラです.
[*] このグラフでは,明らかに妊娠糖尿病のチャレンジテスト(50g糖負荷試験)など,試験条件が異なるものは除いています. データソースは,皆様からご提供いただいたもの,納先生のHP,江部先生のブログ,およびネット上の個人ブログ記事で糖負荷試験の結果を公開しているものから集めました.
糖負荷試験では
主として 0→30分の血糖値/インスリン値,そして1時間後,2時間後の血糖値から,糖尿病や境界型,およびインスリン分泌/抵抗性 などが 数値判定されるわけですが,ここまで広く分布していると,(医療の側としては,どこかで線を引かなければならないという事情はあるにせよ)本当にそれらの数値指標にどれほどの意味があるのだろうかと思ってしまいます.
このデータをどう分析するか
『2型糖尿病って本当にあるのでしょうか?』 の記事 でも紹介したように,Ahlqvist博士は スウェーデン人14,000人のデータを分類するのに, [k-平均法]という手法を用いました. オハジキに例えて説明しましたが,多数のデータを似たもの同志に分ける方法です. 2次元散乱マップで,データに塊があればそれをグループ分けしていくようなものです. ただし あの論文では6つの指標を用いていましたから,6次元空間に配置された14,000個の点を,平衡状態になるまでグループ分けのTry&Errorを繰り返していくというものでした.聞いただけで気が遠くなります.
むしろ,今 目の前にあるこのデータは 画像認識的に 『似た形』で分類していくのがいいのかなと思っております. ただしこれは漠然とした構想です. 統計屋としては腕が鳴る問題ですが,同時に肩と首が凝りそうな予感も. 連休中,じっくり考えてみたいと思います.
コメント