日本に限らず,世界の糖尿病患者は,医者から『あなたは糖尿病です』と告げられる時,その根拠は診断時の血糖値やHbA1cです.WHOの糖尿病診断基準でそうなっているからです.『あなたのインスリン値(IRI)はXXだから,糖尿病だ』と言われる人はいません. 糖尿病がインスリン作用の高低による結果であるにもかかわらず,自分のインスリン分泌量を知っている患者はほとんどいません.
ところが Ahlqvist博士が,従来は それ以上分類不能と思われていた2型糖尿病の患者データベースから,下記6つの指標を用いて;
- GAD抗体(*1)の有無
- 発症年齢
- HbA1c
- BMI
- HOMA2-β(*2)
- HOMA2-IR(*3)
(*1)この抗体は,通常 1型糖尿病の判定に使われます (*2)日本でよく使われるインスリン分泌能の指標=HOMA-βの改良モデル版です.(*3)日本でよく使われるインスリン抵抗性の指標=HOMA-Rの改良モデル版です
Data-driven Cluster Analysis という方法で,先入観を入れずに,ちょうど子供が おはじき遊びをするように『似ているもの同士が集まるように』自動分類させてみたら,実際には5種類の糖尿病があるのではないかと論文発表しました.


この発表は世界の糖尿病医師からは非常に注目されました.従来は説明できなかった,『発症機構と合併症との関係』を解明できる可能性があるからです.
しかし,…そうです,博士が分類に用いた6つの指標の内,HOMA2-βとHOMA2-IRの算出には患者のインスリン分泌量のデータが必要なのです. 現在の医療では 糖尿病患者のインスリン量は全員測定するというわけではありません.この分類が普及すれば,積極的に測定されることになるかもしれませんが,現時点では 医師も患者もインスリン分泌データは豊富ではありません.
別の指標で分類できないか
そこで,考えられるのは 『手元にあるデータで何とかならないか』という発想です.
これをやってみた結果が報告されました.

この報文では,やはりZou博士 が用いた 米国人の糖尿病データベースNHANES(National Health and Nutrition Examination Survey)を使っています.しかも対象者は4,300人と多いです. Zou博士の解析例よりも人数が多いのは,Ahlqvist分類を適用するためには HOMA(-β,-IR)が必要でしたが,この論文では,HOMAデータの使用はあきらめて,下記のデータがあれば 解析対象に含めたからです.
- 発症年齢
- BMI
- 腹囲
- HbA1c
- インスリン使用履歴年数
これなら 糖尿病患者であれば,どの国でも必ずカルテに記録されています.
結果を見ると
上記の5つのパラメータを用いて,Ahlqvist博士と同様に Data-driven Cluster Analysis を実行したところ,下記のようなクラスターに分かれました.
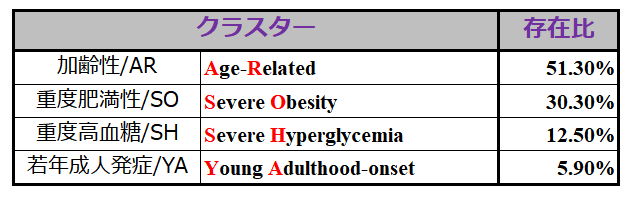
しかしながら,この論文の著者にはまことに失礼ですが,この結果に特に目新しいことは何もありません. 発症年齢が高ければ『加齢性』,BMIが高ければ『肥満性』,HbA1cが高ければ『高血糖性』と呼び変えているだけであり,何もCluster分析という手法を使わなくても,ただそれぞれのパラメータの大きさの順にExcelで並べてもこうなったでしょうから.
この結果を見て 逆に感じるのは,インスリン分泌にかかるパラメータを入れた場合(Ahlqvist博士)と,入れなかった場合(この論文)で,同じ手法を使っても こんなにも結果が違うのか,という点です.
Ahlqvist博士のように発症時点でのインスリン分泌能まで評価に含めれば,早期の重点的治療が行える可能性があります. ところが この論文の分類では,『クラスターに応じた最適の治療法を,発症初期から行う』アイデアが何も出てこないのです.『重度高血糖 SH』型の人に,『血糖値を下げればいいですよ』とは医者でなくてもわかります.
そういう意味で,Ahlqvist博士の着眼点がいかに革新的であったかを教えてくれる論文でした.
[19]に続く
コメント
この解析にわたし自身のデータを放り込んだら、どのグループに分類されるんだろうと興味津々です。
ただ、気になるのが、根拠となるデータなんです。
発症年齢:カルテ上は、2017年に入院した年月日となるでしょう。でも、実際は15年以上前に受けたOGTTで2時間値が200 mg/dlオーバーで糖尿病型でした。ただし、その数年後に受けた血液検査では、HbA1c (NGSP)は5.5%(早朝空腹時血糖値は不明)だったので、糖尿病確定ではありませんでしたが。
HbA1cが6.5%を超えたのがいつか分からないけれど、発覚時にHbA1c 15%、その数年前から体重減少やその他合併症の自覚症状が出ていたので、かなり前から完全な糖尿病を発症していたと思います。
定期健診で早期に発覚した人と、わたしのように長年放置してどうしようもなくなってから発覚した人とでは、同じ発症年齢データでも違いが出そうです。
HbA1c:これも上記と同じく、健診で早期に発覚した人ならそれほど高くないでしょうし、放置していれば高くなりますよね。
BMI:これは発症時のBMIですよね? わたしはおそらくBMIが24ちょいのころに発症したと思いますが、入院したときにはすでに体重が減少しはじめてから数年経っていたので、BMI 18くらいになってしまっていました。なので、カルテ上はその数値になりますが、本当は違うと思います。
インスリン分泌量:入院したときにIRIとCペプチドを測定していますが、当時は高血糖毒性により分泌がかなり悪化していました。(血糖値489 mg/dlに対し、IRI 1.9 µU/ml、Cペプチド 1.07 ng/ml)
今は少し改善していると思います。
ただし、持効型インスリンを使用しているので、早朝空腹時のインスリン分泌量は抑えられているとも思います。
こういう場合のインスリン分泌量は、どの時点でのデータを使うといいんでしょうね。
以上のようなデータのブレがあったとしても、患者の特性を浮かび上がらせることができるというのが、Data-driven Cluster Analysisの強みなのでしょうか?
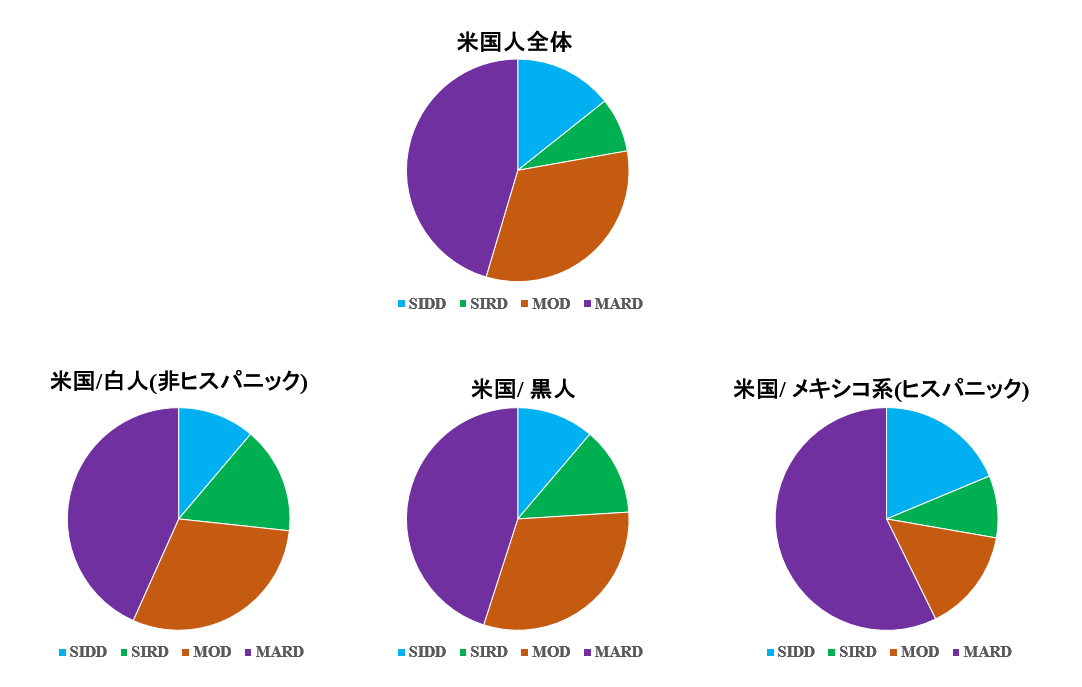
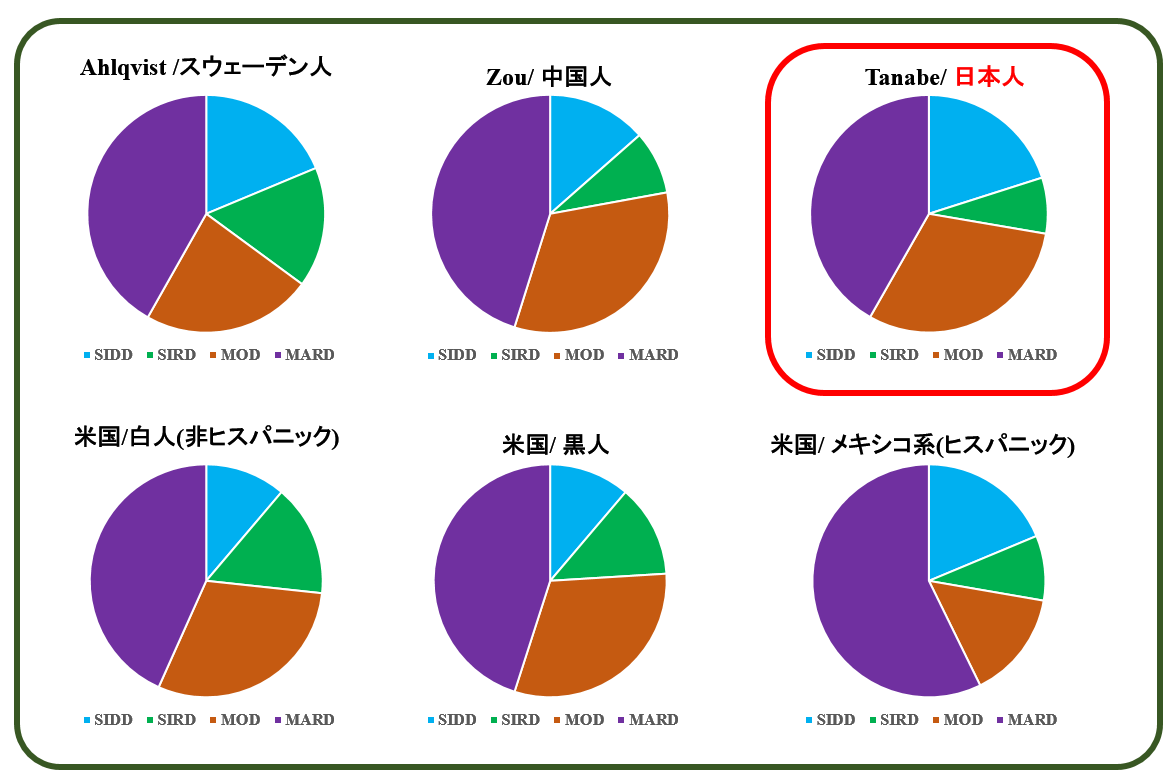
『2型糖尿病』は存在しない[17]で、東アジア人である中国人の解析結果を興味深く見ました。
東アジア人は欧米人に比べてSIDDが多いのかと思っていたら、そうでもないのですね。意外でした。
『2型糖尿病』は存在しない[12]の、GDSにおける登録時と5年後の分類データを見ると、SAID、MOD、MARDに関しては再分類でも変更なしの割合が多く占めていますが、SIDDに関してはほとんどが変更となっていますね。半数がMARDに、残り半数の1/3ずつが、SAIDとMOD、SIDDのまま、という感じです。
流入の方はMODからが一番多く、次いでMARDから、SAIDから少数、といった感じでしょうか。
これを見ると、SIDDに関しては、一時的な糖尿病の進行度合いを示しているのかなと思います。
Data-driven Cluster Analysisは画期的な分析法だと思うので、用いるデータをいろいろ変えてみて(たとえば脂質関連、肝機能関連も含めてみるとか)、遺伝子多型の情報ももっと絡めてさらに分析することで、新たな知見が出てくることを期待したいです。
>以上のようなデータのブレがあったとしても、患者の特性を浮かび上がらせることができる
病態の経時進行については,Onsetから間もない人だけを対象に含めるよう Ahlqvist博士も十分考慮したようです.
>東アジア人である中国人の解析結果
Zou博士は,中国の糖尿病DataBase CNDMDSからデータを取っているのですが,その内容を見ると,かつて一度も糖尿病とも境界型とも言われたことがない人も含まれているとのことです.博士は したがって, SIDDの平均年齢が Ahlqvist博士の例よりもかなり若いのは そのせいだろうと述べています. つまり,ANDISとCNDMDSとを 直接比較するのは無理があるかもしれません.
>SIDDに関してはほとんどが変更
このGDSの結果なのですが,医学的要因だけでなく,『社会環境因子』もっと言えば『栄養状態因子』がからんでしまっているのではないかと考えています.
ドイツは 欧州一の移民大国で,全人口の23%が外国人・移民(出身含む)で,トルコ出身が280万人,シリアからが52万人です.
しかも 無収入の貧困層に限れば35%が移民(+移民出身)なのです.
したがって,GDSのデータで SIDDに含まれる糖尿病患者には 相当 移民の割合が高いと思われます.つまりこれは人種的・遺伝的素因だけでなく,社会環境格差も反映されてしまっている面があるのではないかと思っています.
スウェーデンもまったく同様です.
スウェーデンは 1980年頃まではほとんどの移民は欧州からでした.この時代は スウェーデンも好景気で,あらゆる職種で労働力不足であり,移民もNativeのスウェーデン人も完全雇用で,ほぼ同じ所得水準だったようです.
しかし現在では,移民の就労率は Nativeより15%も低いようです.
スウェーデンもドイツも 移民・難民であっても 国民とまったく同じ医療サービスを提供していますから,登録された糖尿病患者には 移民(及び移民出身)の人も人口比率に応じて またはそれ以上が含まれているはずです.
よって欧州のデータについては常に社会要因が含まれてしまうことに留意すべきと思っています.
Ahlqvist博士が,イラク生まれとスウェーデン生まれの人だけを比較したのは,多分そこに着目したからだと思います.
そして,その結果はやはり イラク生まれの人に SIDDが多いという結果でした.これには遺伝素因だけでなく,環境素因も込みになっているでしょう.
>用いるデータをいろいろ変えてみて(たとえば脂質関連、肝機能関連も含めてみる
これは本当にそう思います. 今までそういう視点で 糖尿病を整理したことがなかったのですから. 実際 日本はデータの質と量だけは,現在世界一のはずです. ところが ANDISやGDSのような統計処理に耐える データベースがありません.J-DREAMSで,これから始めようかという段階です. しかも現時点では 登録施設はまだ60程度.情けないですね.