日本人の2型糖尿病は 本当に1種類か
2型糖尿病って本当にあるのでしょうか? のシリーズ記事でとり上げた通り,スウェーデンのAhlqvist博士は,膨大なデータをクラスター解析という手法で分類して,従来2型糖尿病と言われているものは,実は それぞれ全く異なる6つの病気に分かれることを示しました. これらは 違う病気なのだから,それに最適の治療がなされるべきであると主張するためでした.
そこで,これにならって 我々日本人の糖尿病データは やはり病理・病態の違うものが混在しているのではないかと考え,できるだけ多くの糖負荷試験データを集めて,その類型分類を試みました.
分類の手法 Cluster解析は
最初は糖負荷試験の血糖値及びインスリン曲線の『形』について, Ahlqvist博士 にならってクラスター分類解析 を試みました.これはすべてのデータについて,複数点群のn次元空間における重心を求め,次いで重心の近いもの同士をClusterとして,更にCluster間での重心を求め….という計算を繰り返して,最終的に全体の重心が不動になった時に分類が終了するというものです. いくつに分類されるかは この最終結果までわかりません.
ですが,これ ものすごく大変な計算でした. 欠落のあるデータを除いても.ほぼ100組の糖負荷試験データの 0~120分の血糖値・インスリンデータ点群のすべての組み合わせを計算していくので,コンピュータを何日も終夜運転させても,ほとんど収束の気配がみられません. BitCoinの計算(マイニング)をやっているようなものであり,断念しました.それに代わって;
QUICKI 登場
日本では(そして欧米でも)あまり使われていませんが, QUICKI という指標があります.

空腹時の血糖値とインスリン量から計算するもので,どちらも分母に入っているので,血糖値及びインスリン量が低い(少ない)ほど QUICKIは大きくなります. つまり空腹時にインスリン濃度が低く,それでいて血糖値も低いのなら,よほどインスリン感受性がいいのだろう,というわけです.
他に よく似た指標もあるのですが,インスリン及び血糖値の対数(10を底とする)をとっているのがミソです. インスリン量が非常に低いと,特に1.0を下回ると,その対数は大きな負の値になるので,それだけ QUICKIは大きな数値になります. 欧米白人では,そんな低い空腹時インスリン値はありえないので,この効果は欧米ではほとんど注目されていません. しかし日本人には空腹時インスリンが1.0未満の人は珍しくないのです.
さらに QUICK 30 投入
上記の QUICKIは,少ないインスリンで血糖値をどれほど低く抑えているかを評価することが目的です.そこで,これを拡張して,QUICK30 というしらねのぞるばオリジナルの指標も考えました.

考え方は QUICKIと同じで,糖負荷試験30分の血糖値やインスリンも低ければ低いほどいいだろうということです.
データをプロットしてみました
横軸に QUICKI、縦軸に QUICK 30 を取り,データの揃っている糖負荷試験結果をプロットしました.
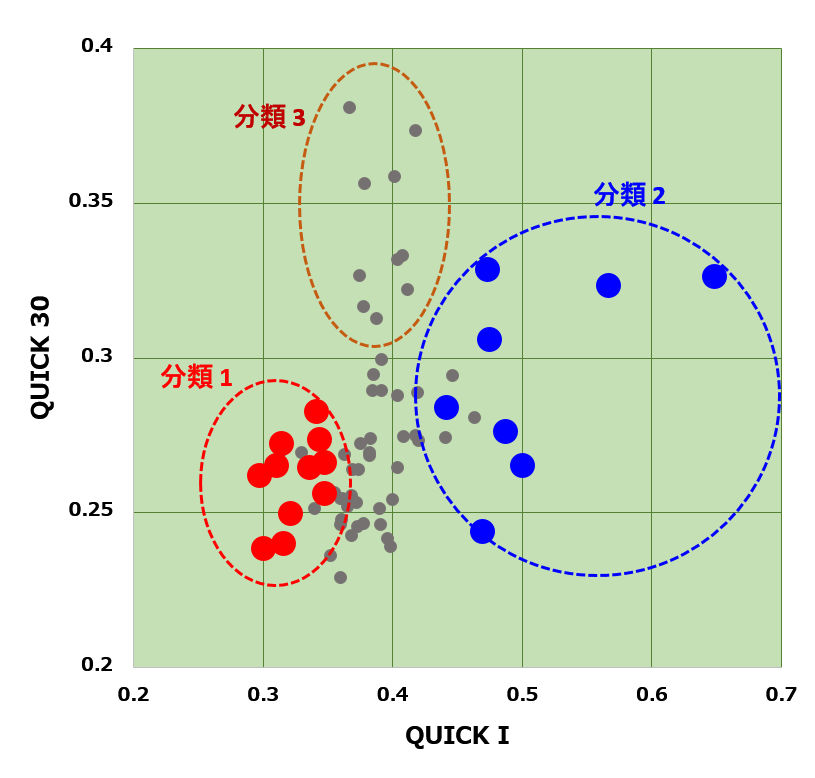
QUICKIもQUICK30も低い,図の左下【分類 1】は,空腹時も糖負荷試験時もインスリン量が多く,その割には血糖値も高いのでこうなります. 赤い●は,明らかに肥満の方で灰色は不明です. この【分類 1】は,インスリン抵抗性が主体の 欧米型 でしょう.
それとは逆に,QUICKIも QUICK30も高い人【分類 2】は,少ないインスリン量にもかかわらず,空腹時/糖負荷試験時 ともに血糖値を低く抑え込めている人です. インスリン感受性が非常に高い人です. 青い●で示したのは,明らかに痩せ型の人で,ほぼ全員です.
【分類 3】は非常に特異です. 空腹時のQUICKIは多くの人とそれほど変わらないのに,糖負荷試験になると QUICK30が高くなる人です. 大量のブドウ糖が流入してくると,それに即応できているわけですから,インスリン感受性よりも,むしろ グルコース感受性 が高い人なのではないでしょうか?
残りの方たちは,以上のどれにも分類できなかったパターンです.ただし,今回のデータでは糖負荷試験の0分,30分しかみていませんが,60分,120分のデータも含めていけば,更に 別れるのかもしれません. あいにく日本の糖負荷試験では,30分以降のインスリンデータは通常測定しないので,データ入手が難しいですが. 大学病院あたりで こういう解析をやってもらいたいものです.

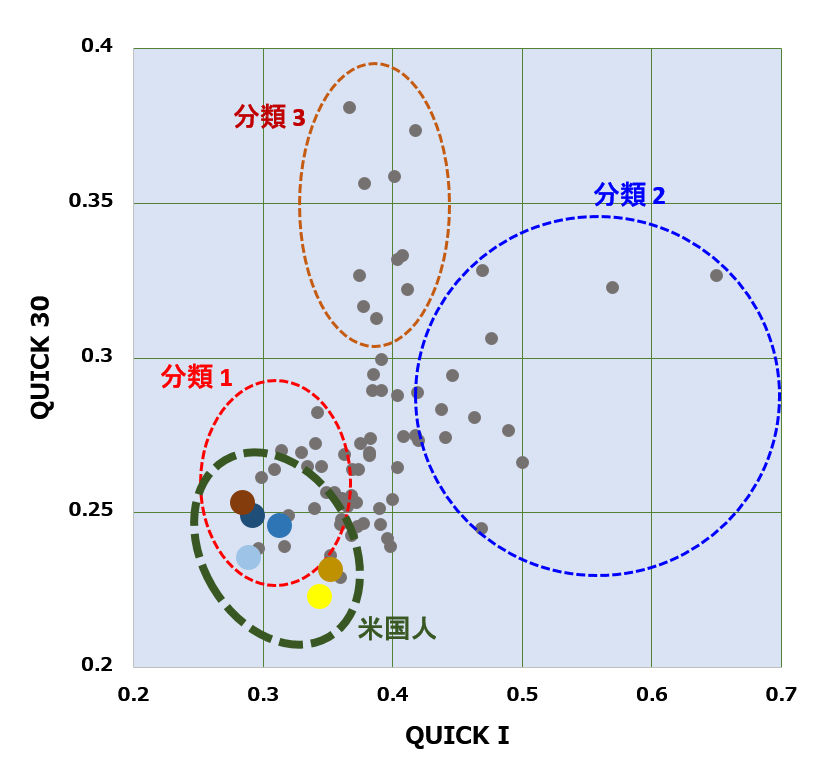
コメント