シンポジウム12:ビッグデータで切り拓く糖尿病診療
学会初日の午後は,これを視聴しました.なにしろ多数の講演・シンポジウムが同時並行なので,同時刻に開催されるシンポジウム8『糖尿病治療において多様な経口血糖降下薬をどう使い分けるか』とどちらにするか最後まで迷いました. しかし,クスリの話は 別の機会もありますので,日本の糖尿病データベースの話をまとまって聞けるこちらにしました.
【1】情報革命(DX)時代の糖尿病診療とその基盤
糖尿病患者の病態・治療を一元的にデータベース化できれば,そのメリットは計り知れません.データが集積されればされるほど より精密な治療が可能になり,医者・患者双方にとって恩恵を受けます. しかし 言うは易し,実際には これまで日本には ごく小規模なデータ集しかありませんでした.
病院ごとにバラバラな用語・カルテの書式・複数の健康保険制度の壁... 情報革命=デジタルトランスフォーメーション(DX)は,掛け声さえかければ 直ちに進展するものではないという,その実情が解説されました.
ここからは私見ですが,マイナンバーカードをすべての国民が取得し それが健康保険証となれば,間違いなく大きな進歩を生むでしょう.しかし ごくプリミティブなミスで躓いてしまいました.昨日も婚活アプリの登録者データが流出したようですが,こういうことが続いていては,国民が不信感を抱くのも もっともな話です.
【2】医療分野における情報処理の方法論-AIを用いたデータ解析を含めて
仮に 日本中の病院のカルテデータ全部を,ある日一斉に厚労省に提出してもらったとしても,それらはデータベースにできません. 理由は各病院ごとに,データ書式がまるで違うからです.共通しているのは 氏名・生年月日・性別くらいで,それ以外は病名・検査データ・治療・処方詳細などが すべてバラバラの書式です.これらをすべて共通カルテ書式に手作業で書き直すことなど不可能です.
そこで,過去データはあきらめるとして,今後は共通書式にしていこうということで 現在SS-MIX2 という標準化が進められています.これは医療にかかるすべてのデータの書式を標準化して,異なる病院でも,電子カルテのソフトが異なっていても 相互にデータ交換できるようにしていこうというものです.
ただし,数値データ(検査値など),あるいは数値コード化できるデータ(統一病名コードなど)についてはこの標準化で進められますが,最近の医療には画像データ(MRI,CTなど)が付き物です.これをどう標準化するかは手付かずです.
さらに難しいのは,医師がカルテに自由記入した文章です.診療科が違えば 同じ略語が別の意味になることすらあります.
したがってこれらについては,機械学習するAIが 高速・正確にデータを読み取って仕訳できるシステムの開発が必要でしょう.これからの課題です.
【3】AIによる糖尿病網膜症の診断
ところが一方で,【AIによる自動画像診断】が既に実用化している分野があります. 眼底写真画像から,網膜症や出血を完全に自動判定できるシステムが既に存在しているのです. 眼底写真に四角形や楕円形はありません.昔からあの画像形式ですし,被写体(=眼底網膜)も常に同じなのでプログラム判定に向いていたのです.この分野では 米国や中国が進んでいて,眼科医院で,眼底カメラで撮影してもらうと,その場でリアルタイムに眼底異常が判定・表示されます. またベルギーでは,何と眼鏡屋に眼底カメラがあり,眼鏡を買う前に診断してもらえるそうです.
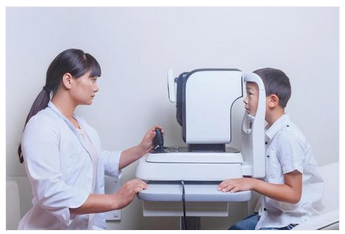
日本ではまだそこまで進んでいません.しかし皮肉なことに,外国で進展している眼底画像自動診断に使われている機器は,ほとんど日本製の眼底カメラだそうです.
【4】NDB(National Data Base)とは何か
日本でもっとも大規模な医療情報データベースである,保険診療報酬請求(レセプト)データを集積した厚労省の『NDB OpenData 』が紹介されていました.
本ブログでも,かつて このレセプトデータを分析しましたが;
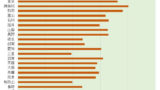
病名が記載されていない,あるいは記載されていてもあてにならない,という欠点を除けば,ほぼ全国民の保険診療データをもれなく集積した 実に貴重なデータベースです.
この講演では,NDBを分析したところ,都道府県によって,糖尿病の検査項目に大きな差があり,それらに合理的理由があるとは思えないと指摘していました.
実際 私も 上記記事の『ご当地 糖尿病治療事情』に書いたように,都道府県によって 糖尿病 治療薬の処方に随分バラツキがあることに気づきました.
【5】診療録直結型全国糖尿病データベース事業(J-DREAMS)の現状と展望
上記【1】で,『日本には ごく小規模なデータ集しかなかった』と書きましたが,その原因は各病院がバラバラの(電子)カルテを記載しているからです. つまり,何か全国規模での調査をするとなると,いちいち『所定の記入用紙』が配られて,各病院ではカルテを見ながら,手作業でそれに記入するという,実にあほらしい手作業が発生します.
なので,必然的に,
- 全国一斉ではなく サンプリングして少数の施設だけを対象にする
- 及び/又は
- 手間を省くため 記入事項を極めて簡素なものにする
しかありません.だから『ごく小規模』になってしまうのです.
しかし,患者を診ながら,医師が自分のデスクのPC上の電子カルテに記入したことが,そのまま自動登録されていくのであれば,無理なくデータが集積できる---これが J-DREAMSの仕組みです.
これなら誰にも苦労をかけずに 信頼性の高いデータベースが自然に蓄積されていきます.
ただし,そのJ-DREAMSですら,まだ課題もあるようです. 現在 全国62施設で7万人の患者データが逐次集積されつつありますが,参加施設をもっと広げようにも,J-DREAMSで採用している上記のSS-MIX2準拠の標準化カルテを導入していない病院の方が多いことが障害になっているようです.
【6】Real World Dataを駆使した糖尿病診療・療養指導のエビデンス確立
この記事でも取り上げた Ahlqvist博士の画期的な糖尿病新分類は;

スウエーデンでは,すべての国民の医療データが,国民背番号により 完全に一元化されていたからこそ可能になったものでした.
この例からもわかるように,実臨床に役立つデータとは,臨床試験のように特殊な『エリート患者集団』から集めたデータではなくて,実際の多種多様な患者から集めたデータ,つまりReal World Dataなのです.
[3]に続く

コメント