【この記事は 第68回 日本糖尿病学会年次学術集会のレポートではなく,講演を聴講した ぞるばの感想です】
ぞるばは数学が苦手です. なので,工学部に進学する時も 物理系の学科ではなく,化学系を選んだのですが,量子化学の教科書を見た時には..絶望.

1ページ目から 数式ばっかし.
ことほど左様に数学には弱いのですが,この講演では数学が雪崩を打って突撃してきました.具体的には医学の世界にもAIが普及しており,それを医学文献検索にも活用したという事例です.

今回の学会のシンポジウム7:『糖尿病診療における人工知能およびデジタル医療の展望』の2番目の講演です.
まさか糖尿病学会の会場で「リーマン空間」と言う言葉を聞くとは思わなかった.
私は学会の講演を聴講する際には,講演のすべてをその場で理解して,かつ完全に記憶できるわけもないので,メモをとっています. もちろん速記などできませんから,実際には講演を聞き流しながら,講演では何が語られたのかを後になって詳しく調べるのに必要な手掛かり情報だけを ハガキ大のノートに書き留めていきます. 会場はスライドを投影するため薄暗いので,手元は見ずに(見えない) スライドの文献引用情報などを走り書きしていくのです.
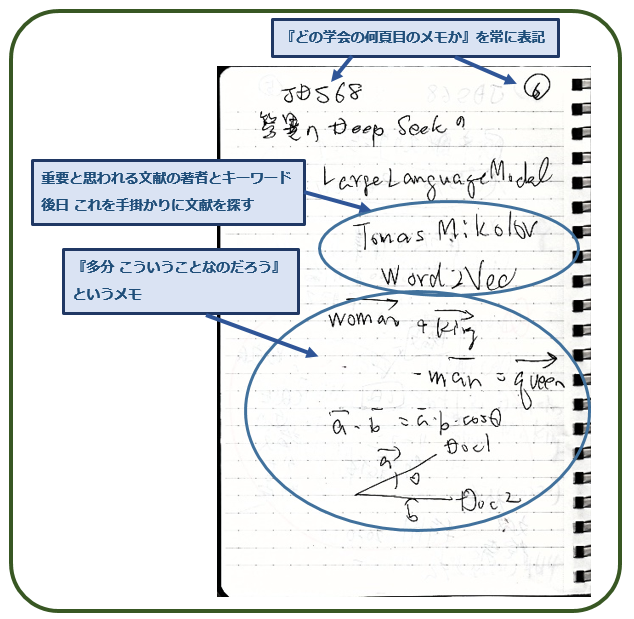
これは,その講演 S7-2を聞きながら 書き留めたメモの一部です.今学会では,こういうメモを100頁ほどとりました.
Tomas Mikolovという著者名,そして Word2Vec(tor)という言葉が,講演の中で重要な意味を持つと思えたので,それだけを書き留めています.
そして どうやらキーと思われる論文を探し当てました.この文献を読んだとは申しません. 「眺めた」だけです. そして 以下の文は,ぞるばがこの論文を「眺めた」後,夜中にうなされているたわごとのようなものと思ってください.
前回記事で,『システマティック・レビュー』を行う際には,膨大な論文を検索して,その内容が目的とするものなのかを判定しなければならない,と書きました. つまり 文献の大意を正確に読み取る必要があるのです.しかしながら 1本,2本の文献ならともかく,数百本,時に数千本の論文ともなると,これは大変な作業です.そこで それを 昨今流行のAIで何とかならないのか,とこう考えるのは自然ですね.
- この論文には何が書いてあるのか.
- この論文とあの論文では どこがどう違うのか
具体例では「この論文は,SGLT2阻害薬は腎臓病に有効かどうかを厳密に調べたものと言えるのか」などという疑問に答えてくれるものなのかどうか,という問題です.
インデックス分類
どの学術論文でも,まず文献のタイトル,著者名,概要(Abstract)と続き,その後に Keywords:というものが示されています.こういう具合です.

このキーワードを見れば,この文献が『何について書かれたものか』はよく分かります. しかしこれだけでは『何が書かれているのか』までは分かりません. キーワード・インデックスとは,あくまでも分類指標であって,内容分析まではできないのです.
N-グラム
そこで,文章が何を述べているのかをもっと詳しく判定すべく考案されたのが 『N-グラム法』です.
N-グラム法の「グラム」は重量単位のgではなくて,モノグラム Monogram,テレグラム Telegram(電報)などの単語に使われるグラムの意味で,語源はギリシャ語の
gramma =書かれたもの,文字.転じてそれらにより表現された情報
という意味です.そしてN-グラム法とは,ある文章に登場する単語をすべて数え上げて,どの単語がどれくらいの頻度で使われているかを統計分析して,その内容を推論する方法です.
2つの異なる文献で,それぞれに登場する単語の種類と登場頻度順位が一致すれば,内容は似通っているのだろうと判定します.
ただし純粋に統計的手法ですから,文意までは判定できないのが弱みです.
- 最近 地球環境に対する危機要因として過度な気候温暖化が懸念されている.
- 最近 過度に気候温暖化を懸念することが 地球環境にむしろ危機要因となっている
意地悪な例をあげましたが,この2つの文章は ほとんど同じ単語を使っているにもかかわらず,正反対の内容です.単語の登場頻度だけでは,この二つの違いを判定できません.
Word2Vec
このような問題を解決するために考えられたのが『単語同士の関係性』です.単語にはどんな意味が含まれているのか,そして単語同士の類似性・関連性を数値で表せるようにしたのが,Tomas MikolovのWord2Vec,すなわち 単語(Word)を多数の成分を持つベクトル(Vector)として扱うという発想です.

ベクトルとは,複数の成分を持ち,大きさだけでなく「方向」も表せます.二次元ベクトルは2つの成分(x,y)を持ち,三次元ベクトルであれば3つの成分(x,y,z)を持ちます.
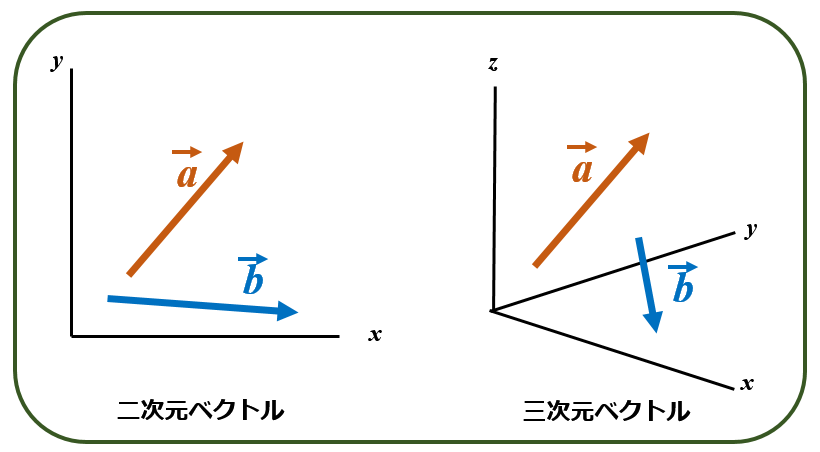
単語は多くの意味を含んでいます. 例えば 「犬」という単語は,「哺乳類」「俊足」「ワンと鳴く」などです. この単語をN次元のベクトル,つまり多数のN個の成分の集合体として取り扱えます.
そして,こうすることにより,ある単語と別の単語との意味が近いのか遠いのかは,ベクトルの内積で表現できるのです.
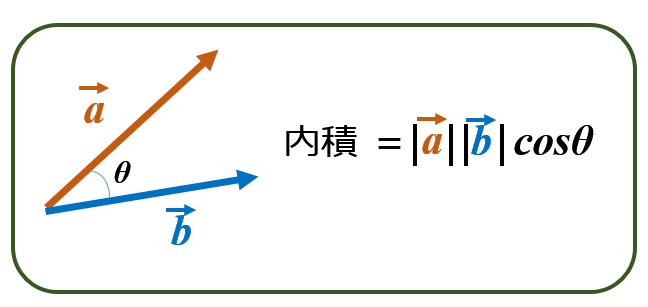
内積が大きければ(θが小さければ),ベクトルaで表される単語と ベクトルbで表される単語の意味は近いことを意味し,内積がゼロならば(θが90°ならば,cosθ=0なので) 2つの単語は無関係,そして内積が負ならば(θが 90~180°ならば)2つの単語は反対の意味を持つと言えます.
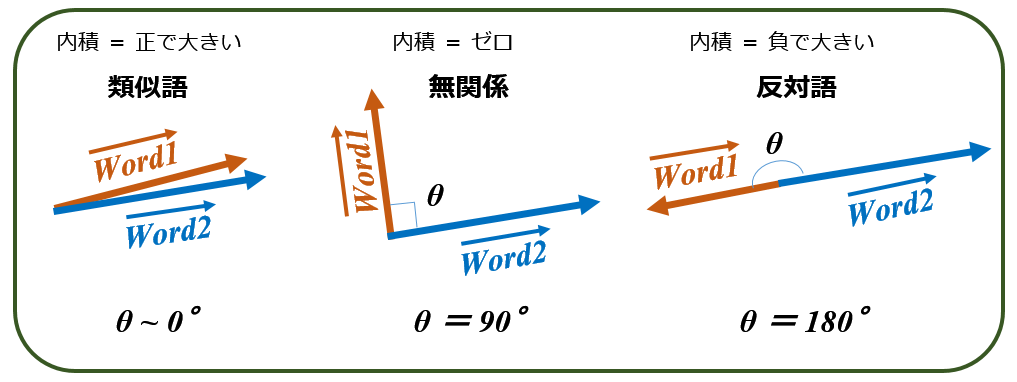
つまり単語と単語の関係を数値で取り扱えるのです.このことは 人間が読み書きする自然な文章を,コンピュータが理解できる数値計算として扱えることになります. (実際の単語ベクトルは N次元であることに注意)
実際 上記 Mikolovの文献では,
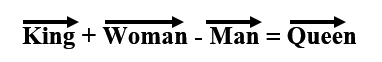
という単語間の演算が可能なことが示されています.
このようにして,文章に含まれる単語をベクトルの集合体としてとらえると,複数の文章,つまり複数の医学文献を比較して,内容が似ているのか,無関係なのか,正反対なのかも「数値として定量的に」評価できることになります.
前述の例としてあげた「この論文は,SGLT2阻害薬は腎臓病に有効かどうかを厳密に調べたものと言えるのか」という文章に対して,100本の文献だろうが,10,000本の文献だろうが,【その問題に対して答えを出している順番】に並べることが可能になるのです.
研究者が徹夜して「膨大な文献を読み込んで内容を把握し,システマティック・レビューに採用すべきかどうかを判断する」という作業を,コンピュータが順番をつけてある程度判定してくれる,ということになります.
実際 川崎医大の神田先生は,この方法による文献検索法で特許を出願し 成立させています.
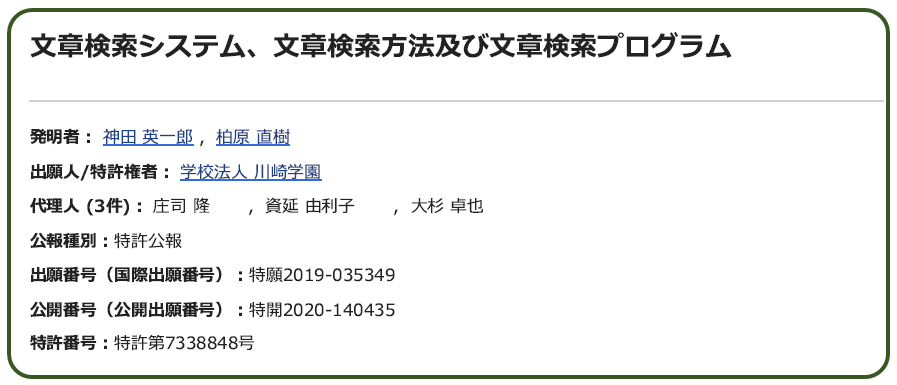
この講演を聞いている間は,いったい何の話をしているのか さっぱりわかりませんでしたが,講演のメモに書き留めた断片的な言葉をてがかりにしてここまで調べたところで,ようやく『あ,あの時は そういう話をしていたのか』とわかりました. 確実に時代から取り残されておりますね.


コメント