
【この記事は 第68回 日本糖尿病学会年次学術集会のレポートではなく,講演を聴講した ぞるばの感想です 】
[カバーイラスト (C) ぽりごん さん]
第68回日本糖尿病学会 年次学術集会の感想記事です.

川崎医大の神田英一郎先生による シンポジウム7:『糖尿病診療における人工知能およびデジタル医療の展望』の2番目の講演です. 川崎医大のサーバーに蓄積されたCKD(Chronic Kidney Disease;慢性腎臓病)の臨床情報データベース =J-CKD 21大学,529,000件のデータを活用して,
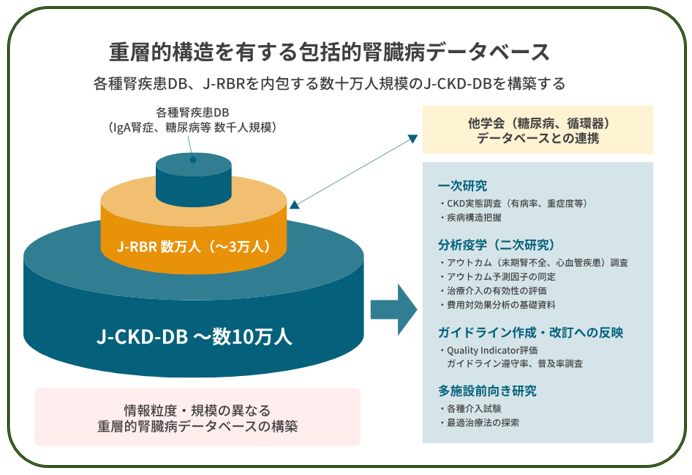
機械学習によりCKDの予後を予測するプログラムを開発していることが報告されました.
実際その研究成果から多くの論文が発表されています.
ガイドラインのエビデンス
ところで,上記J-CKDの成果は,日本腎臓学会が公表している診療ガイドラインにも反映されています.
そして,このガイドラインを作成する際にもAIが活用されているのです.
通常ガイドラインに採用するエビデンスは,信頼性が高いもの,バイアスがかかっていないものが求められます.
いい加減な論文を根拠にして 診療ガイドラインを定めたらとんでもないことになるからです.
この『いい加減な論文を排除して,信頼性の高い文献だけを収集する』方法がシステマティック・レビュー Systematic Review です.
【システマティック】という名前を冠しているのは,一切の予断・バイアスを排して,系統的かつ無作為に評価するという意味です.都合のよい論文だけを集めれば,自分が出したいと思っている結論はいかようにでもなりますからね.
通常 システマティック・レビューを行う際には,一定のキーワードを定めて,それに適合するすべての論文を,MedLine,PubMed などの大規模文献データベースから集めます.公平を期すため,この収集段階では 一切排除は行いません.
そしてこれらの論文に対して,客観的な判定指標を用いて適合しないものを振るい落としていきます.たとえば,「試験の方法は明確で詳細か」「データに欠落はないか」など,つまり内容があやふやなもの,信頼性の低いものを排除しておきます.
不眠不休
そしてここからが大変です. ここまでのふるい分けで残った論文の内容が,ガイドライン作成の根拠(エビデンス)として採用するのにふさわしいかどうかを,1件1件内容を精読して選定していくのです.
この作業は膨大です. 下の例は,「2型糖尿病患者が運動療法を行った場合に,C反応性タンパク質・炎症性サイトカイン・アディポカインにどのような影響があるのか」という問題について,ランダム化比較試験の文献を集めてメタアナリシス(メタ解析)を行った報告です.2型糖尿病患者には 運動が推奨されますが,それはいいことばかりではなく,デメリットはないのかという疑問に答えることを目的としています.

下図は,無作為に集めた論文から該当するものだけをふるい分けるまでの途中経過です.
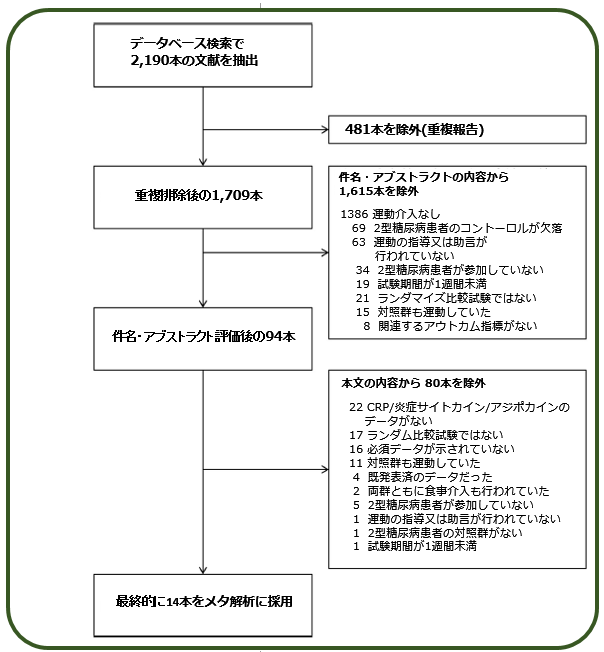
ご覧の通り,最初に集めた2,190本の論文の内,システマティック・レビューを行って 最終的にメタ解析に使えると判明したものは わずか14本でした.
どういう理由でこの14本に絞ったのかは,図中に示されていますが,この判定は論文の斜め読みでは不可能です.まさに一文・一語まで精読しないといけないのです.
メタ解析というと,他人の論文をチャチャッと集めて それをまとめればいいのだろうと思われがちですが,説得力のある解析結果を出すためには,このシステマティック・レビューの段階がもっとも大変です. この例では最初に2,190本の論文が集められたのですが,これが1万本を越える場合も珍しくはありません. どういう基準でふるい分けるのかを徹底的に議論してチェックリストを作成したうえで,さらにたった一人では不可能な膨大な作業なので,多数の選定担当者が不眠不休ですべての論文を片っ端から読み込んでいくのです.
冒頭の神田先生の講演では,従来は 人海戦術で行われていたこの文献の読み込み・比較を,AIによって解決しようという試みが紹介されておりました. ですが,それは「数学の世界」です.ただいま頭痛と闘いながら理解しようとしているので,その内容は次の記事にでも(出せるのか?)

コメント